
 Peter Norvig, you might have heard of him, or felt his presence on stormy mountain tops. Among several other accomplishments, he is the creator of Norvig’s Law, the world record holder for the longest palindrome, former head of computational sciences research at NASA, ballet dancer, current director of research at Google, & a human being.
Peter Norvig, you might have heard of him, or felt his presence on stormy mountain tops. Among several other accomplishments, he is the creator of Norvig’s Law, the world record holder for the longest palindrome, former head of computational sciences research at NASA, ballet dancer, current director of research at Google, & a human being.
SMX West Day 2 kicked off with a keynote from the genial Mr. Norvig, while Search Engine Land’s Chris Sherman & Danny Sullivan picked his behemoth brain. The keynote was split into two parts, first a laundry list of notable Google Research accomplishments, followed by a Q & A session with Danny & Chris.

21 Projects from Google Research in 15 Minutes
#1 Person Finder – After the Chile earthquake , Google built an app engine application where you can hook up with people you know in Chile and find out if they are okay. Was developed in a short amount of time.
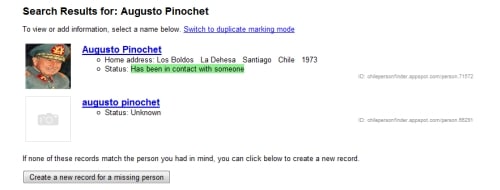
#2 Google Power Meter – Plug in a device into your house and find out how much power you use each day. In some cases, after installing the meter, users starting cutting down on consumption by 25%.
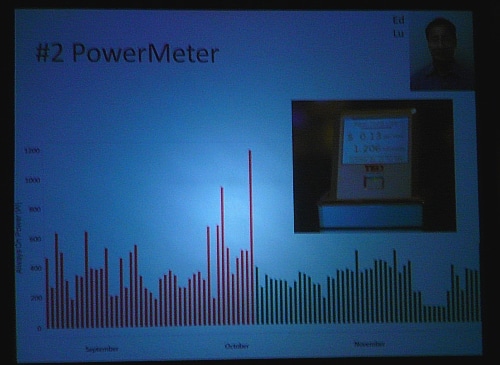
3. Earth Engine – An app that works as an overlay with Google Earth data, displays with deforestation data for instance, tons of potential.
4. Trikes and Snowmobiles – Google is taking Google Streetview where no car has gone before. They had a snowmobile pulling steetview data at the Olympics, apparently.
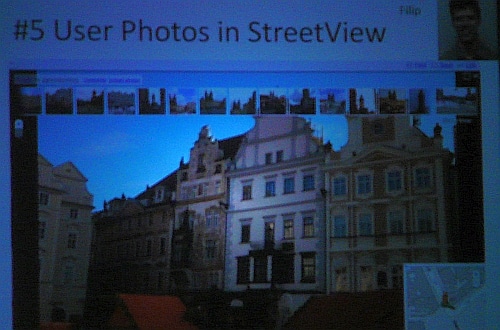
5. User Photos In Google Streetview
6. Image Swirl – Google’s image reconnection software – do a search query, get images and they are then put together in piles of images that look similar (Matt note – this one can get tricky)
7. Web Scale Image Annotation – Google has taken a set of images and the queries that triggered them and then matched them up across several languages, more like an inter-lingual translation model.
8. Image Rotation Captcha – Google is currently looking at ways to make captcha’s easier, like showing a picture that’s rotated and your task is to rotate it correctly.

9. Google Goggles – This is an application that runs on a phone with a camera, when you take a picture with a camera in San Francisco-Â the application it will tell you it’s the Golden Gate Bridge ( if it’s actually in the picture).
10. Discontinuous Video Screen Carving – This is sort of like squishing pictures down to a smaller aspect ratio in Photoshop, but for video. You can take 1 frame in a video and you can squish it together, and track that from 1 frame to the next
11. Sharing Cluster Data -Â A high level view of data on all jobs running in Google’s cluster – how much memory the jobs took, how much time, wow, useful.
12. App Inventor for Android – An introductory program development environment currently being used in some highschool and college dev classes. Really, it’s a visual programming language for Android where you can snap blocks together and build working applications.
13. Speech Recognition on Phones – Enough said.
14. Punctuation & Capitalization in transcribed speech – Now they’ve built a language model that gets periods, commas and quotes right in transcribed speech.
15. A Translating phone – Google has talked about this possibility & though they’re not there yet they’ve got the two pieces – machine translation and voice recognition, just have to put them together.
16. Low Resource MT(Machine Translation) For Yiddish – There’s not a lot of written text in yiddish – 98% is actually hebrew, google was able to do Yiddish translation by falling back on other languages that share similar attributes
17. Sound Understanding – Go to Youtube, search for something that sounds like a rooster and they’ll give you that. They produce a sonogram for each video & then couple that with their image processing features.
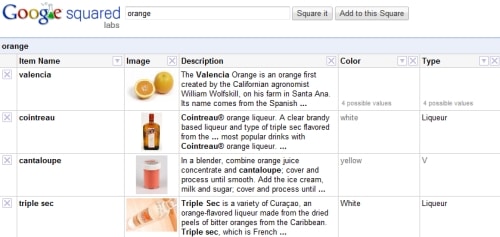
18. Google Squared – This is essentially Google building a database of attributes by scraping off pages
19. Clustering– A project for clustering of words within a context. If you type in the Whistler – clusters around the painting, the city in Canada, the bird. Really awesome.
20. Attribution Extraction – For example, this project can recognize a cluster for basic foods, then find & sort attributes in documents - pounds, cup, kinds, bowls & in queries – nutritional value, health benefits, glycemic index etc.
21. Browser size – showing percentages of what people can view on your page compared to browser size.

In conclusion, Peter proffers this quote
” You can observe a lot just by watching” – Yogi Berra
*Question & Answer with Peter Norvig*
Chris Sherman – Can you give us a broad overview of how you approach research project?
Peter – Anyone can go out and start a project on their own. People are open and when you get an accumulation of enough people saying something is interesting, then they start developing. One thing that makes it easier is the infrastructure we’ve built that makes it easier for people to have experiments.
We’re not looking at a powerpoint slide, it’s a demo. Sure it’s not finished, it has some ragged edges, but it’s a demo. At Google, they already want to build the tool, so when you start experimenting, you’re immediately running it all over the web. One thing unique to Google is that we run production services out of research. Once we have something that we think is pretty good in research, we don’t roll it over to engineering, we keep the same team and run it out of research.
Chris – Any of the things you showed us today has a practical application. How do you decide the balance of where you focus your efforts?
Peter – I think we’re always pushing hard to create something useful.
Danny Sullivan – What do you think are some of the biggest things to come out of the 20% time (Matt note – Google encourages its employees and engineers to spend 20% of their time on other projects that interest them)
Peter – One story is, Paul Buccheit did both GMail and Adsense in his 20% time because he was frustrated that it was easier to search the web than it was his own email. Then he said, “Well how are we going to pay for this, maybe show ads on the side, and then they said why not on the SERPs too?” He doesn’t think that was 20% time, but as soon as he had the idea, it transferred over to 100% time.
Chris – How much are Larry and Sergey hands on, today?
Peter – They’re very hands on. They see themselves as having two goals. One is the long range direction of where the company is heading. Two, they’re trying to evaluate as many projects as they can. They’re just as involved as ever, to them they’re life hasn’t changed. To the rest of us, it has because the interval that they can get around to any one project is a lot longer.
Chris – You have research facilities all over the world, are they segmented by region or project?
Peter -Certainly you want to have experts in the local language and culture & that ranges from the mundane – getting all the translations right to novel types of search product. There’s also the aspect of “we need more engineers, and we can’t hire them all in one place.”
Chris – Google has moved very quickly to incorporate realtime and social search, but you don’t have the same signals with that type of stuff, it seems like that would be a big challenge to come up with the relevant signals without endangering your core search product?
Peter – One thing I think is still overhyped is Pagerank. People think you do this computation on the web graph and order all pages by that. That computation is important, but it’s just one of many things. We never felt that it was such a big factor, it’s got a catchy name, but we’ve always looked at all available data. The fact that there aren’t legacy links (in realtime and social), we don’t think of that much different. What enables that is the infrastructures we’ve built that makes it possible to do real time. Look, when I started, the index was once a month.
Danny – It’s interesting when you talk about Pagerank. Is it time for someone to put together a catchier name for Google Rank?
Peter – I think that’s right, there’s confusion that there’s this one component called Pagerank, but that also, all of the algorithm is somehow based on Pagerank.
Chris – With the Caffeine structure update, how much does your group put into that? Also, we hear that Caffeine is is in place by now but also some conflicting data saying it isn’t.
Peter – We have one data center, testing very well, & we’ll be rolling out further. Specifically, who in my group is working on that? It turns out, that system programming stuff is not done typically in research.
Danny – Back to the ideas of signals and rankings, do you have some that you can share that people might not realize? People understand link aspect, but like with local search, you’re take local citations etc, what can you share with us?
Peter – In a lot of cases, you can think of it as saying we are manufacturing links that way, we can recognize this as a business or something else. I showed some of the recognition of objects and they’re attributes (idea #20). With Google books, when you’re scanning books, they don’t have hyperlinks, but they do have bibliographies, so we build links that way. I know that this community is interested in finding just the right keywords & synonyms, but also know we’re trying to help to do that as well.
Chris – Is there a division between your focus on the core search vs advertising vs other products?
Peter – There’s certainly a fundamental distinction that this side of the house is given this side of the page – this other group is given this side of the page. You can’t have your editorial team mixing with your advertising team, the teams are working separately to try to keep those distinct.
Chris – IS there more work put into ads vs something else?
Peter – I don’t know if there is in terms of total numbers. T think there are different types of challenges, but we do think of those two as being the real core, then the periphery is other products like Gmail.
Danny – Are we getting to the point where having the index of objects?
Peter– I think we’re starting to get there, where we had the objects in there and their attributes. Google Squared is one example were you can see companies, and then their executives and revenues, but I think we are moving in that direction. That’s driven by a lot of factors. People want better answers, to do more with them and we want to support these types of queries, like “Show me these companies and rank them by revenue.”
Chris – You have a background in AI, 20 years ago speech recognition was called improbable. What kinds of things are you seeing as problems that will take a while to crack.
Peter – Vision is the big problem, speech recognition and translation. The vision problem for still images and video images is challenging both for computation issues – so much more data involved in a video. Then also it’s just messier, trying to parse these pictures up into objects. Words are very nice, you can differentiate much easier
Danny – Got any solutions for email, I think people would like to have something to process email to deal with all that stuff they have on their plate.
Peter – I had an intern working on the project because that really bugs me. (Matt note – this is a joke, go ahead, you can laugh) Watch out for future stuff we’ll have that we’re still playing with. The other thing, is email really the right tool? Maybe just slashing that all down and starting all over will help. If the new model is wave or buzz or twitter? I don’t know what the right answer is, sometimes starting over is the next step.
Chris – Your teams, are they using wave internally?
Peter – Some certainly are, people are trying to figure it out where it works best. When you start something new you have these choices – do i make a google wave, do a make a gdoc, do a make a google site? I think we’re going to have to see some consolidation, you don’t make the choice with technology, you make the choice with content.
Danny – We do have all these differnt tools and more and more information, and let’s not forget video. Who’s winning, the new information blowing in or the ability to keep up?
Peter – We’ll, we’re managing the ability to search through it very well. wW’ll need more help in really finding the best things. I subscribe to an email mailing list, but what I’d really like to subsrcibe to is “What email in this mailing list have been read by 70% of the users.” More ways of describing what’s useful and what’s not.
Chris – Sergey talked about embedding a chip in your head to search google, anyone working on that?
Peter – Not yet, Jim Reese is gone so no more brain surgeons.
Danny – If you want to grow up and be a search engineer, how do you go about insuring people are ready to work at google?
Peter – Ties with the academic industry. In other industries, you get trained in school and you get a job pretty quickly. People that come to google often say “Wow, everything i knew is wrong.”
Chris – Do you move people in around in google? Microsoft is very well built for moving people from project to project.
Peter – We encourage that, we like to keep our projects short so you can finish one and move up or move on. I think I found more often than not, you finish a 3 month project and you say “wow so many ideas came up from that, I want to work heer for my next 3 month project.”
Danny – What do you see as next in search, are we going to have dramatic changes finally?
Peter – I don’t know, I think you see the search results page becoming more interesting and varied, not just a list of 10 links now. I think you’ll see the result page look more like a newspaper page. That’s one aspect. Mobile is also driving things hard, you’ve got such a small screen, that will require more of a partnership to make it work. I think we’re going to have to learn a lot more about what your personal context is.








